
The Types and The Methods of Regularization in Machine Learning
Machine learning is a powerful and popular field that uses computers to learn from data and perform tasks that require human intelligence. However, machine learning is not perfect, and it can sometimes suffer from problems such as overfitting and underfitting.
One way to overcome these problems is to use regularization in machine learning. Regularization is a technique that modifies the machine learning model to make it simpler and more robust. It also helps to prevent overfitting and underfitting. Regularization can also improve the performance and accuracy of the machine learning model and reduce the computational cost and time.
But what is regularization in machine learning, and how does it work? What are the types and methods of regularization in machine learning? If these are something that you want to know, then I have you covered! Keep on reading this blog till the end to learn more…
What is Regularization in Machine Learning?

Regularization in machine learning is a technique to balance the fit and complexity of the model. It helps to trade off the bias and variance of the model.
Overfitting is when the model learns too much from the training data and generalizes poorly to new data. Underfitting is when the model learns very little from the data and misses the patterns or relationships in the data.
Bias is the error from the simplifications or generalizations of the model. Variance is the error from the sensitivity or variability of the model to the noise in the data.
A good machine learning model should have low bias and low variance. This means it should fit the data well and generalize well to new data.
Why do You Need to Regularize in Machine Learning?

The goal of regularization in machine learning is to find the optimal balance between the fit and the complexity of the machine learning model. It also helps to achieve the best trade-off between the bias and the variance of the machine learning model.
Overfitting is when the machine learning model learns too much from the training data and fails to generalize well to new or unseen data. Underfitting is when the machine learning model learns so little from the training data that it fails to capture the relationships and underlying patterns.
Bias is the error that results from the simplifying assumptions or the generalizations made by the machine learning model. Variance is the error that results from the sensitivity or the variability of the machine learning model to the random fluctuations or the noise in the data.
A good machine learning model should have low bias and low variance, which means it should fit the data well and generalize well to new or unseen data.
What are the Types of Regularization in Machine Learning?
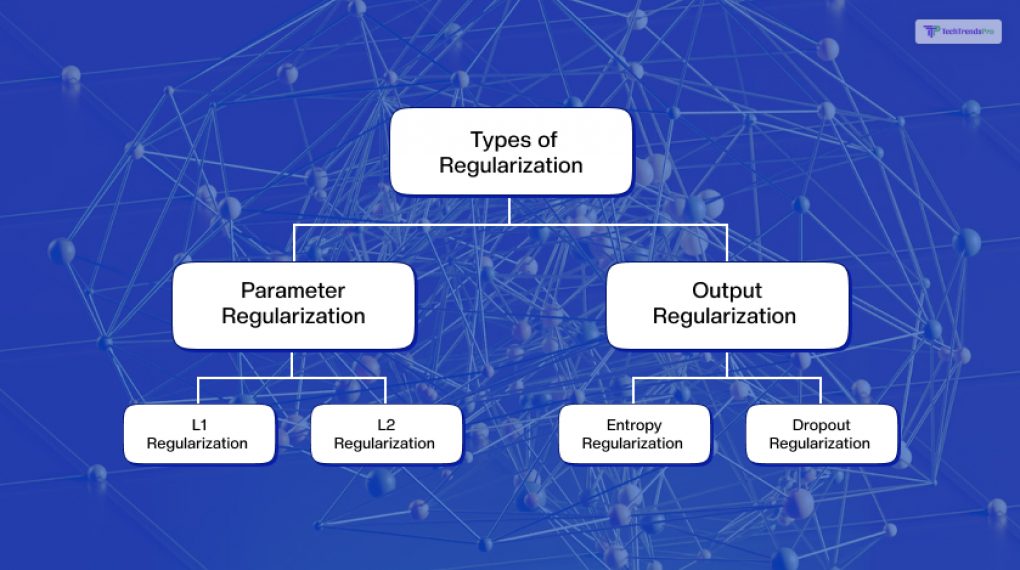
Regularization in machine learning can be of two types, based on the penalty term: parameter regularization and output regularization.
Parameter regularization
Parameter regularization is a type that adds a penalty term to the objective or loss function of the model. This is a function of the model parameters, like the weights or coefficients.
Parameter regularization works by shrinking or sparsifying the model parameters. This makes the model simpler, and more robust, and prevents overfitting and underfitting.
Parameter regularization can be of two subtypes, based on the penalty term: L1 regularization and L2 regularization.
L1 regularization
This subtype adds a penalty term to the objective or loss function of the model. This is the sum of the absolute values of the model parameters, like the weights or coefficients.
L1 regularization works by shrinking the model parameters to zero, which makes some of them zero and sparsifies the model. This regularization is also called lasso regularization or LASSO.
L1 regularization is useful for feature selection. This is selecting the model’s most relevant or important features or variables. L1 regularization is also useful for high-dimensional or sparse data. It has many features or variables, but few of them are non-zero or significant.
L2 regularization
This subtype adds a penalty term to the objective or loss function of the model. This is the sum of the squares of the model parameters, like the weights or coefficients.
L2 regularization works by shrinking the model parameters to zero, but not exactly zero. This makes them smaller but not sparse. This regularization is also called ridge regularization or RIDGE.
L2 regularization is useful for reducing the variance or noise of the model and improving its stability and robustness.
It is also useful for multicollinearity or correlation. This is when some features or variables are linearly dependent or related, which can cause problems for the model.
Output regularization
This type adds a penalty term to the objective or loss function of the model, which is a function of the model output, like the predictions or probabilities.
Output regularization works by smoothing or modifying the model output, which makes the model more conservative and less confident. It also prevents overfitting and underfitting. Output regularization can be of two subtypes, based on the penalty term: entropy regularization and dropout regularization.
Entropy regularization
This subtype adds a penalty term to the objective or loss function of the model, which is the entropy or uncertainty of the model output, like the predictions or probabilities.
Entropy regularization increases the entropy or uncertainty of the model output. It thus makes the output more uniform or balanced and less skewed or extreme.
Entropy regularization is also called maximum entropy regularization or MaxEnt. This type of regularization is useful for improving the diversity and coverage of the model. It is also needed to avoid the domination or exclusion of some classes or categories.
Entropy regularization is also useful for imbalanced or skewed data. This unequal or disproportionate distribution of classes or categories can cause problems for the model.
Dropout regularization
This subtype adds a penalty term to the objective or loss function of the model, which is the dropout or random removal of some of the model output, like the predictions or probabilities.
Dropout regularization works by dropping out or removing some of the model output with a probability. This makes the output more sparse or incomplete and less dense or complete. This regularization is also called the dropout or dropout layer.
Dropout regularization is useful for reducing the co-adaptation or dependency of the model output. It also helps improve the independence and robustness of the model.
Dropout regularization is also useful for overfitting or overcomplexity, which is when the model learns too much from the data and generalizes poorly to new or unseen data.
Other Types of Regularization in Machine Learning
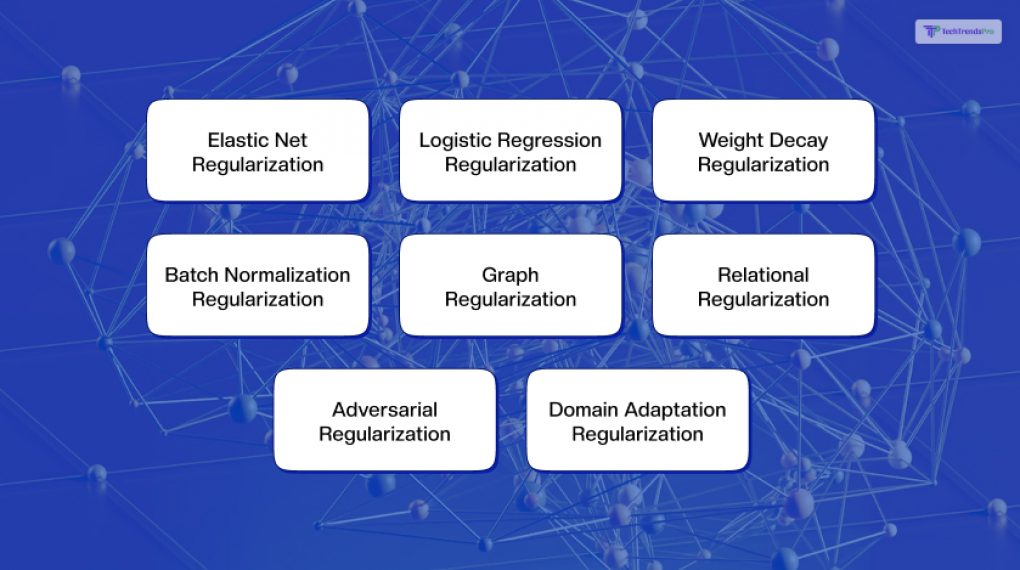
The ones I mentioned above are the types and subtypes of regularization in machine learning, based on the type and the penalty term’s form.
However, there are also other types and subtypes of regularization in machine learning, based on other criteria, such as the type of the machine learning model, the type of the data, or the type of the problem.
For example, there are regularization techniques for linear models, like elastic net regularization, which combines L1 and L2 regularization, or logistic regression regularization, which is L2 regularization for logistic regression models.
There are also regularization techniques for neural networks. For instance, there is weight decay regularization, which is L2 regularization for neural networks, or batch normalization regularization, which normalizes the inputs of each layer.
There are also regularization techniques for structured data. For example, there is graph regularization, which incorporates the graph structure or relationships of the data into the model, or relational regularization, which enforces the consistency or coherence of the model across different data sources or domains.
There are also regularization techniques for unstructured data. Some examples are adversarial regularization, which generates synthetic or fake data that is similar but not identical to the real data and trains the model to distinguish them, or domain adaptation regularization, which adapts the model to different data distributions or domains.
What are the Methods of Regularization in Machine Learning?

Regularization in machine learning is a technique that modifies the machine learning model to make it simpler and more robust. Additionally, it helps to prevent overfitting and underfitting.
Regularization can be implemented or applied using various methods or approaches. This depends on the type and the form of the penalty term and the type and the form of the machine learning model.
Here are some of the common methods or approaches of regularization in machine learning:
Regularization parameter
Regularization parameter is the method or approach of regularization that involves tuning or optimizing the hyperparameter that controls the strength and the impact of the penalty term.
The hyperparameter is usually denoted by lambda or alpha. It determines how much the model parameters or the model output are penalized or modified by the regularization technique.
The optimal value of the hyperparameter can be found by using various techniques, such as cross-validation, grid search, or random search.
Cross-validation is a technique that splits the data into multiple subsets and uses some of them for training and some of them for testing. It also evaluates the performance of the model on different values of the hyperparameter.
Grid search is a technique that tries out all possible combinations of values of the hyperparameter and selects the one that gives the best performance.
Random search is a technique that tries out random combinations of values of the hyperparameter and selects the one that gives the best performance.
Feature selection
Secondly, the Feature Selection method of regularization involves selecting a subset of features or variables that are most relevant or important for the machine learning ne learning model and discarding the rest.
Feature selection can reduce the machine learning model’s complexity and dimensionality, It can improve its performance and interpretability. Feature selection can be done using various techniques, such as filter, wrapper, or embedded methods.
Filter methods are techniques that rank the features based on some criteria, such as correlation, variance, or information gain, and select the top-ranked features.
Wrapper methods are techniques that use a machine learning model to evaluate the features. It then selects the best subset of features which gives the best performance.
Embedded methods are techniques that combine feature selection and model training and select the features that are most relevant for the model.
Early stopping
Early stopping is the method of regularization that involves stopping the training of the machine learning model before it reaches the maximum number of iterations or epochs. It also involves selecting the model that gives the best performance on the validation data before time.
Early stopping can prevent the machine learning model from overfitting or underfitting the data and improve its generalization ability.
Early stopping can be done by using various techniques. Some of them are validation-based early stopping, patience-based early stopping, or delta-based early stopping.
Validation-based early stopping is a technique that monitors the validation error or the validation accuracy of the machine learning model and stops the training when the validation error or the validation accuracy stops improving or starts deteriorating.
Patience-based early stopping is a technique that limits the number of iterations or epochs the machine learning model can go without improving the validation error or the validation accuracy and stops the training when the limit is reached.
Delta-based early stopping is a technique that sets a threshold on the change or the difference of the validation error or the validation accuracy between two consecutive iterations or epochs and stops the training when the change or the difference is below the threshold.
Wrapping It Up!
Regularization in machine learning is a technique to overcome overfitting and underfitting and improve the model’s performance and reliability. Regularization adds a penalty term to the model’s objective or loss function, reducing the model’s complexity and flexibility. It prevents it from learning too much or too little from the data.
Based on the penalty term, regularization can be of two types: parameter regularization and output regularization. Parameter regularization adds a penalty term that is a function of the model parameters, like the weights or coefficients, and shrinks or sparsifies them. Output regularization adds a penalty term that is a function of the model output, like the predictions or probabilities, and smooths or modifies it.
Depending on the penalty term, model type, and form, regularization can be applied using various methods or approaches. Some common methods or approaches of regularization are regularization parameters, feature selection, and early stopping.
Read Also:



